
Orquestración
Introducción
Como hemos visto antes, tenemos un conjunto de servidores que pueden alojar nuestras aplicaciones y ahora podemos elegir el servidor o servidores en los que desplegarlas o redesplegarlas.
Sin embargo, todavía tenemos que elegir el servidor físico disponible en el que desplegar eni-todo y comprobar que dispone de recursos suficientes. Debemos comprobar el espacio en disco, los puertos a configurar, la actualización del DNS interno, etc.
Si tenemos que realizar una operación de mantenimiento, necesitamos cambiar la carga, es decir, las aplicaciones existentes, del servidor que se va a actualizar a uno o varios servidores que seguirán disponibles y podrán alojar nuestras aplicaciones mientras dure la operación de mantenimiento, todo ello, por supuesto, sin detener el servicio.
Este recorrido por los servidores disponibles para elegir el candidato en el que desplegar nuestra aplicación se realiza de forma manual o semimanual, con comandos de Ansible a los servidores candidatos.
Automatizar este tipo de tareas es la función de un orquestador.
En este capítulo veremos qué es un orquestador, cómo funciona y nos introduciremos en el más conocido y potente de todos ellos: Kubernetes.
Abstracciones de orquestación
El principio de un orquestador de sistemas de información es crear abstracciones que permitan manipular, distribuir y prestar servicios informáticos a través de redes informáticas, muy a menudo mediante HTTP, pero no exclusivamente. A menudo se habla de la complejidad de mantener una máquina de estados de forma distribuida.
Una de las ideas que subyacen a la utilización de un orquestador es la posibilidad de hacer un uso óptimo de los recursos disponibles. El objetivo es, a través de diversas restricciones, permitir un mecanismo de toma de decisiones que responda de forma óptima al contexto. Estos elementos se detallarán en la sección Scheduler.
Existen dos categorías principales de herramientas de orquestación:
-
Herramientas de acceso remoto (como Ansible), que acceden a servidores remotos para realizar operaciones específicas (playbooks).
-
Herramientas (como Puppet), que utilizan un agente local para garantizar la "coherencia" del servidor ante estados definidos.
Como la arquitectura física, técnica y de software puede ser variada (PowerPC, AMD y otros, tipo de procesador - x86, ARM, etc. -), es necesario sin embargo utilizar ciertas abstracciones, cuyo objetivo es, a la vez, simplificar y garantizar que las abstracciones comunes se puedan tratar por lotes.
1. Abstracción del servidor
La primera abstracción...
¿Automatización u orquestación?
La distinción entre la automatización de los procesos de instalación, actualización, distribución, etc. y un sistema de orquestación, reside principalmente en la voluntad o capacidad de formalizar las reglas de gestión que permiten tomar decisiones sobre la asignación de recursos.
Una de las dificultades de la informática de empresa es la previsibilidad de las decisiones. Por ello, a menudo es más fácil contar con procesos automatizados, pero en los que la toma de decisiones sigue estando en manos de los operadores (como ocurre en el capítulo Exposición y reparto). Este método de funcionamiento tiende a mantener una sensación de control. Es una sensación que no hay que descuidar, porque la confianza que tenga en sus herramientas es, sin duda, el factor principal de su usabilidad. Sin embargo, los ordenadores tienen una capacidad de procesamiento mucho mayor y, a veces, las limitaciones humanas obligan a pasar a la orquestación. El límite es impreciso, depende de la experiencia y de los niveles de armonización entre aplicaciones, pero el umbral está ahí.
Fuerza
La fuerza de un orquestador reside, por supuesto, en su facilidad de uso y su capacidad para distribuir correctamente las cargas informáticas en todo un clúster. Es una herramienta muy fácil...
Batalla de orquestadores
De 2011 a 2014, Docker cobró cada vez más importancia como herramienta para encapsular aplicaciones en la nube, con soluciones como Amazon ECS. Las ofertas de alojamiento de Docker empiezan a florecer en Microsoft e IBM.
De 2015 a 2018, comenzó la guerra de los orquestadores. Hay un gran número de soluciones de orquestación que compiten entre sí en términos de funcionalidad. Dado que Docker se puede manipular fácilmente a través de sus API, la implementación de un orquestador se convierte en una necesidad. Docker se diseñó específicamente para facilitar el despliegue y la hiperdensificación de aplicaciones. Entre los principales candidatos para la orquestación se encuentran:
-
CoreOS, creador de etcd, de la versión Tectonic y del motor de contenedores rkt, creador de la versión inmutable de CoreOS, posteriormente de los operadores (operators) dentro de Kubernetes.
-
Rancher con Gattle, que está notablemente detrás de la democratización de la expresión metafórica "think cattle not pets" (piensa en ganado, no en mascotas) para definir el nuevo paradigma de las relaciones entre los operadores y sus servidores. Este orquestador está muy orientado a la supervisión y es uno de los primeros en ofrecer una supervisión totalmente integrada y herramientas centralizadas de gestión...
Mecanismos de entornos distribuidos
1. Consenso
En un sistema distribuido, mantener la coherencia del estado del sistema es un proceso complejo que debe tener en cuenta la latencia potencial de algunos de los miembros y los posibles problemas de fallos. Históricamente, se han utilizado herramientas hash (MD5, shasum) y de paridad, para comprobar que los archivos no se han corrompido en una red reconocida como poco fiable (TCP/IP).
El mecanismo que garantiza esta coherencia se denomina consenso. Existen varios mecanismos técnicos para mantener el consenso. Vamos a presentar Paxos y Raft.
2. Paxos
Paxos es un mecanismo de consenso en un sistema distribuido, definido en 1989 y perfeccionado en 1998 (The Part-Time Parliament - Leslie Lamport. Este artículo apareció en ACM Transactions on Computer Systems 16, 2 (mayo de 1998), 133-169. Se hicieron correcciones menores el 29 de agosto de 2000).
Paxos requiere varias funciones:
-
El Proposer crea el mensaje generado por una solicitud de escritura de un cliente del sistema.
-
Varios Acceptors juntos constituyen uno o varios quorums. Si hay varios quórums, al menos un Acceptor por quórum debe pertenecer a varios quórums.
-
Los Learners son los servidores encargados de la escritura solicitada.
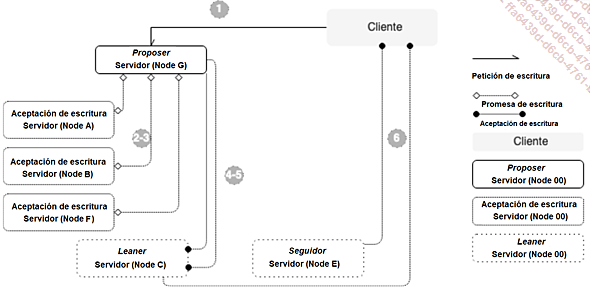
Figura 1: Llegar a un consenso con Paxos
Cuando un cliente pide a un miembro que escriba un mensaje, la persona que se hace cargo de esta petición se convierte en el Proposer (1) y también...
Scheduler
El papel del planificador o scheduler es encontrar el recurso que necesita para instanciar la carga de cálculo entre los recursos disponibles. Para ello, es necesario formalizar un proceso de toma de decisiones dentro de Kubernetes. Este proceso dentro de Kubernetes se denomina policy.
Dentro de un clúster Kubernetes, el planificador busca el nodo en el que puede desplegar sus pods (conjunto atómico de 1 a n contenedores). Realiza una acción de filtrado y una acción de cálculo de pouds para elegir el nodo adecuado. Para ello, utiliza predicados y criterios de priorización. Filtra todos los nodos disponibles en función de estos predicados (por ejemplo, si un nodo tiene recursos suficientes). A continuación, asigna una puntuación a los nodos candidatos en función de los criterios de priorización y sus pesos, para elegir el mejor candidato.
He aquí un ejemplo de archivo de política:
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : " PodFitsHostPorts"},
{"name" : " PodFitsResources"},
{"name" : " MaxCSIVolumeCount"}, ...Introducción a Kubernetes
Una herramienta como Kubernetes comenzó como una abstracción para permitir que los contenedores se ejecuten independientemente de la ubicación física en la que se encuentran.
Es una herramienta creada inicialmente por Google y ofrecida como código abierto. Se inspiró en Borg (una referencia a la serie Star Trek TNG), el orquestador interno de Google.
1. Arquitectura
Por lo tanto, Kubernetes es inicialmente un orquestador de contenedores. En Kubernetes, todos los servidores son nodos (nodes).
Los controladores (control-plane nodes) son responsables del funcionamiento de los componentes principales:
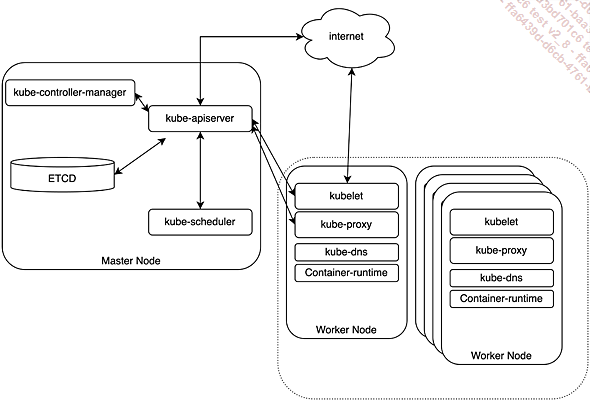
Figura 4: Arquitectura de Kubernetes
-
El kube-apiserver es el puerto de comunicación entre los distintos componentes. Actúa como intermediario entre el kube-controller, el kube-scheduler y el etcd, por un lado, y el kubelet y el kube-proxy, por otro; estos dos últimos se encuentran en nodos workers y son responsables de los intercambios con otros nodos.
-
El kube-controller es el "garante" de los estados del clúster. Mediante un bucle infinito, comprueba y mantiene la coherencia de los objetos del clúster.
-
El kube-scheduler es responsable de asignar los pods a los nodos, de acuerdo con las restricciones y políticas de programación.
-
La base de datos etcd (individual o clúster) es la base de datos clave-valor que contiene el estado del clúster.
Los workers, normalmente llamados nodos de trabajo, se encargan de instanciar los pods según las peticiones del controlador.
-
El kubelet instanciará los pods a través de su motor de contenedores y basándose en las descripciones que le envíe el "controlador" (control-plane). También instancia los pods "estáticos" definidos localmente en su carpeta dedicada (/etc/kubernetes/manifest).
-
El kube-proxy es el componente responsable de conectar los nodos al API y configurar los elementos internos de enrutamiento y del port-mapping.
-
El pod (que se puede traducir como "cápsula") es la unidad atómica de ejecución dentro de Kubernetes. Con el tiempo, se ha enriquecido, pero en el nivel más simple, es una descripción de los recursos que se pueden utilizar por uno o más contenedores.
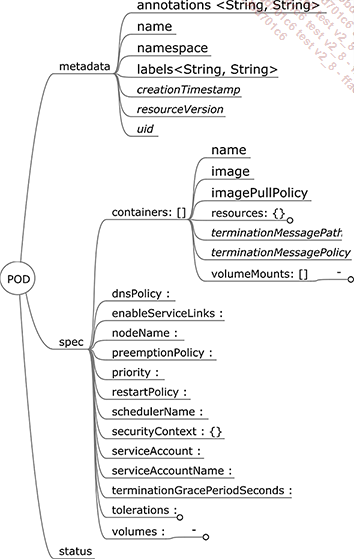
Figura 5: Especificación de un pod
Los recursos de un POD son la CPU...
Introducción a Kubernetes
1. kubectl
Kubectl, la herramienta cliente de Kubernetes, es una herramienta de línea de comandos para gestionar la interacción con nuestro clúster. Aunque creemos que es preferible tener el cliente en nuestro entorno, es posible utilizar este cliente desde nuestro Minikube con el comando minikube kubectl --, sin necesidad de instalarlo.
Esta función también es útil cuando necesitamos utilizar diferentes versiones del cliente.
$ minikube kubectl -- get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane,master 65m v1.20.2 El cliente kubectl realiza las llamadas al API de Kubernetes por nosotros, de una forma mucho más sencilla. Todo lo que hace kubectl se puede hacer con llamadas directas (vía curl, wget o programáticamente) al API.
2. Llamadas al API
Kubernetes dispone de una API REST que permite a los usuarios interactuar con el clúster. Este API permite leer, crear o modificar los object resources del clúster: todos los recursos (objetos) que Kubernetes puede manipular. Puede obtener una lista de los tipos de recursos de objetos del clúster mediante el comando kubectl api-resources:
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints ...