
Centralizar los registros de actividad
Objetivos del capítulo y requisitos previos
En capítulos anteriores, el lector ha aprendido a consultar los registros de actividad de los contenedores. También ha aprendido que un contenedor tenía una vida útil particularmente corta.
En realidad, un simple crash provocará la creación de un nuevo contenedor y la imposibilidad de consultar el registro de actividad, que podría haber explicado este crash. Para hacer frente a esta eventualidad, Kubernetes ofrece la posibilidad de centralizar los registros de actividad.
Se estudiarán las diferentes soluciones nativas a los servicios gestionados:
-
Google Stackdriver
-
Azure Monitor
-
Amazon Cloudwatch
En el caso de Google y Azure, estas soluciones se preconfiguran cuando se crea el clúster. En el caso de Amazon, se estudiará una propuesta de solución con el servicio Cloudwatch.
En el caso de un clúster alojado (on premise), al lector se le presentarán dos soluciones:
-
Loki (desarrollado por la empresa de software Grafana)
-
Elasticsearch
Ambas soluciones tienen sus ventajas e inconvenientes. Se abordarán un poco más adelante, en la sección dedicada a la configuración de Loki.
Principio de la centralización de los registros de actividad
1. Arquitectura
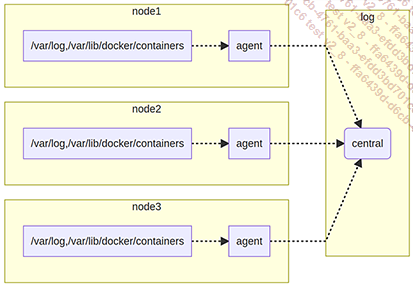
Principio de funcionamiento de la centralización de la actividad de los diferentes nodos
Todas las soluciones siguientes se basan en el mismo mecanismo:
-
Recopilar los registros de actividad en cada nodo usando un agente.
-
Enviar estos registros de actividad a un punto de almacenamiento centralizado.
Algunos clústeres están preconfigurados (este suele ser el caso de los servicios gestionados), mientras que otros se deben configurar (como en el caso de Amazon o los clústeres instalados manualmente).
2. Características del agente desplegado
El agente encargado de este trabajo se basa en un objeto DaemonSet. Cada nodo lanza un pod con acceso a los directorios de la máquina host:
-
El directorio /var/lib/docker/containers para acceder a los registros de los contenedores.
-
El directorio /var/log para acceder a los logs de la máquina.
El pod guarda archivos de registro de actividad para saber dónde está el trabajo de recopilación de los logs.
En el caso de Fluentd, estos archivos se presentan como archivos .pos almacenados en la máquina principal en el directorio /var/log. Estos archivos de posición están en formato texto y contienen una línea por registro de actividad, donde figuran los siguientes campos separados por tabulaciones:
-
El nombre del registro de actividad siguiente.
-
La última...
Centralización en el cloud
1. Centralización con ayuda de un servicio gestionado
Los proveedores de la nube ofrecen herramientas para centralizar los registros de actividad. Algunos de estos servicios se definen de forma nativa cuando se crea el clúster (Google o Azure), mientras que otros requieren una configuración específica (Amazon).
Esta es la solución preferida al inicio (especialmente cuando la integración ya está hecha por defecto). Sin embargo, debe tener en cuenta los costes que este tipo de solución puede generar, especialmente porque estas herramientas no siempre tienen la facilidad de uso o el poder de una solución basada en Elasticsearch y Kibana.
2. Google Stackdriver
a. Presentación de Stackdriver
La centralización de los registros de actividad en Google se realiza mediante la herramienta Stackdriver. De forma predeterminada, los registros se envían a este servicio cuando se crea el clúster.
La centralización de los registros de actividad requiere que la API de Stackdriver esté activa. Visite la página Stackdriver Logging API de la consola Google Cloud Console.
b. Pod Fluentbit (clúster GKE)
El envío de logs de un clúster de GKE se basa en el software Fluentbit, desplegado con un DaemonSet. Los pods asociados se etiquetan con app=fluent-bit-gke y se inician en el espacio de nombres del kube-system.
Ha aquí el comando para consultar estos pods:
$ kubectl -n kube-system get pods -l k8s-app=fluentbit-gke A continuación, se muestra un ejemplo de resultado en un clúster compuesto por tres nodos:
NAME READY STATUS RESTARTS AGE
fluentbit-gke-d8bdg 2/2 Running 0 6d21h
fluentbit-gke-pwrpw 2/2 Running 0 6d21h
fluentbit-gke-wgj98 2/2 Running 0 6d21h c. Consultar los diarios de actividad
Se puede acceder a los registros del clúster en la consola...
Centralizar los diarios de actividad con Loki
1. Presentación de Loki
a. Origen de Loki
Loki es una herramienta desarrollada por la empresa que creó Grafana. El objetivo de Loki es ofrecer una herramienta similar a Prometheus, pero para registros de actividad.
Al igual que Prometheus, Loki recupera y almacena las etiquetas de los pods. También es muy ligero y consume muy pocos recursos (especialmente en comparación con una solución basada en Elasticsearch).
Sin embargo, el producto tiene una restricción: no indexa el contenido de los logs. Por lo tanto, no hay posibilidad de hacer una investigación textual directa.
b. Loki vs Elasticsearch
Lo que puede parecer una desventaja, también es su punto fuerte. Debido a que no hay trabajo de indexación, el proceso de almacenamiento de logs es muy eficiente, desde el punto de vista del consumo de recursos.
Donde un proceso de Loki consumirá menos de 1 GB de memoria, los procesos de Elasticsearch pueden aumentar fácilmente este valor a más de 10 GB de memoria.
Aun así, no se trata de si Loki debe reemplazar a Elasticsearch, sino de conocer los pros y los contras. Por ejemplo, no olvide que Loki no indexa el texto. Para este tipo de necesidad, Elasticsearch sigue siendo indispensable.
c. Consejo de utilización
Debido al consumo de las etiquetas de los pods, la búsqueda se puede realizar con ellas.
Una buena práctica con esta herramienta...
Centralizar los registros de actividad con Elasticsearch
1. Advertencias y limitaciones
Esta sección no pretende enseñar el funcionamiento general de Elasticsearch. Solo se debe ver como una ayuda para su implementación en Kubernetes.
Lo invitamos a consultar la documentación oficial de Elasticsearch para conocer y respetar las buenas prácticas.
2. Acerca de Elasticsearch
Elasticsearch es un servidor basado en Lucene. Este tipo de base de datos permite almacenar elementos de forma no estructurada. En la implementación de Kubernetes, se puede usar para centralizar registros de actividad de los contenedores.
En adelante, la centralización de los logs se realizará con un agente Filebeat desplegado en cada nodo del clúster (hay otras soluciones posibles con fluent-bit o fluentd, por ejemplo). El despliegue se hace de manera natural con un objeto DaemonSet.
La implementación de Elasticsearch necesita cierta cantidad de recursos. No se recomienda desplegarlo en un clúster formado por nodos que no tengan, al menos, 2 CPU y 4 GB de memoria.
3. Desplegar los componentes Elasticsearch
a. Instalar Elasticsearch
En caso de que ya tenga un clúster de Elasticsearch externo a Kubernetes, puede pasar a la siguiente sección.
La instalación de Elasticsearch se realizará mediante el chart Helm elasttic/elasticsearch. Antes de instalar el chart, añada la fuente de los paquetes usando el siguiente comando:
$ helm install elasticsearch elastic/elasticsearch El chart utilizado despliega los pods sin limitaciones de memoria o CPU.
Para limitar el consumo, utilice las siguientes afirmaciones:
resources:
limits:
cpu: "1"
memory: "2048Mi"
requests:
cpu: "200m"
memory: "1536Mi"
# Add this configuration to change permissions...Gestionar Elasticsearch
1. Acceder a la interfaz Cerebro
Los pods asociados a Cerebro llevan la etiqueta app=cerebro.
Consulte la lista de pods asociados a esta etiqueta en el espacio de nombres elasticsearch:
$ kubectl get pods A continuación, se muestra un ejemplo de resultado:
NAME READY STATUS RESTARTS AGE
cerebro-64bd586f6-5fjt6 1/1 Running 0 7m37s La aplicación Cerebro usa el puerto 9000 para trabajar. Abra este puerto usando la instrucción port-forward en el pod de Cerebro:
$ kubectl -n elasticsearch port-forward deploy/cerebro 9000 Seguidamente, introduzca la dirección http://localhost:9000 en un navegador.
Página de inicio de Cerebro
Indique la dirección de Elasticsearch (http://elasticsearch-master:9200), para acceder a la interfaz de administración de los índices.
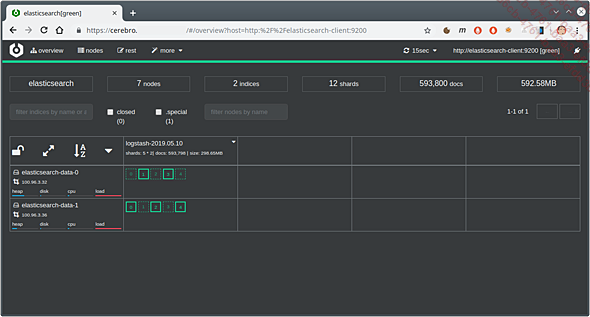
Ejemplo de visualización con Cerebro de un clúster de Elasticsearch desplegado en Kubernetes
2. Utilizar Kibana
a. Acceder a la interfaz de Kibana
Para iniciar sesión en Kibana, ejecute el siguiente comando:
$ kubectl -n elasticsearch port-forward deploy/kibana-kibana 5601...