
Malwares: estudio del código malintencionado
Introducción
Es una ilusión pensar que un capítulo sería suficiente para cubrir el estudio del código malicioso.
La diversidad de los lenguajes de programación, sistemas operativos, arquitecturas de procesadores, el uso de programas legítimos de forma no apropiada y la amplísima variedad de vulnerabilidades hacen que exista un número casi infinito de combinaciones que convierten en ineficaz, si no imposible, un enfoque sistemático.
Además, es común pensar de manera errónea que un antivirus es una solución de protección.
Efectivamente, un antivirus no es un escudo que evita que se contamine, sino que cumple una función de vacuna: evita que ejecute malware conocido.
El año 2020 fue una brillante demostración de los límites de la vacunación: ninguna vacuna protegía contra el Covid-19 a pesar de que existían muchas, y estar vacunado contra el tétanos no le protege de la infección por coronavirus.
Surgen entonces dos preguntas:
"¿En qué caso es imposible desarrollar una vacuna eficaz?" y "¿A qué sigo siendo vulnerable?"
Para responder, debe comprender los límites de las técnicas de detección de malware y saber que, de media, un antivirus solo lo protege de aproximadamente un tercio del código malicioso.
La analogía de la vacuna...
¿Qué es un malware?
El código malicioso, en inglés malicious software, a menudo abreviado como malware, es un programa que realiza acciones maliciosas.
Una definición que realmente no ayuda a avanzar.
El contenido y comportamiento del malware depende en gran medida del propósito de su autor.
El conjunto de herramientas, programas, procesos, técnicas, tácticas de un atacante o grupo de atacantes se abrevia como TTP (en inglés: Tactics, Techniques, and Procedures).
Es posible clasificar los códigos maliciosos en función de diferentes métodos. En nuestro lenguaje cotidiano, nos referimos a varios de ellos.
No es raro oír hablar de gusanos (imaginando la propagación de una máquina a otra), lo que se corresponde con el enfoque epidemiológico; credentials stealers (programas de robo de identidades), un enfoque centrado en el objetivo del atacante; o incluso de backdoors (puertas de atrás), que se corresponde con la descripción técnica de la modificación añadida al sistema para tomar el control.
La mejor clasificación
Es una pregunta compleja y la respuesta, si no es 42, es "la que más le convenga" o, para los más creativos, "la suya".
Sin embargo, las clasificaciones existentes son muy adecuadas.
Un enfoque epidemiológico tiene en cuenta los factores que favorecen la propagación de una infección e involucra al agente patógeno, al huésped, al medio, a los vectores de transmisión, etc.
De esta manera, podemos lograr una clasificación, una taxonomía para los puristas. También encontramos en nuestra vida cotidiana las denominaciones virus, gusanos, vectores de propagación, etc. para hablar de la amenaza informática.
La ventaja de este enfoque es que permite anticipar la forma de contener la amenaza teniendo en cuenta la posible progresión de la amenaza en el parque informático.
Enfoques técnicos como MITRE Att&ck o CKC (Cyber Kill Chain) de Lockheed Martin permiten clasificar los malware en función de las trazas o rastros que dejan en el sistema y combinarlos con la fase del ataque en curso.
Estos pasos son los mismos que gobiernan un pentest: reconocimiento, enumeración, explotación, instalación, movimientos laterales, etc.
El CKC permanece en un nivel macro, la matriz Att&ck haciendo zoom hasta el artefacto del sistema.
Por ejemplo, el malware se clasifica en función del uso de program...
La detección por base de conocimiento
Spoiler: no funciona.
Uno de los enfoques más simples es mantener una lista de todos los códigos maliciosos pasados, presentes y futuros.
Gracias a la llamada función checksum o suma de control (o hash en inglés), es posible verificar la integridad de un archivo. Una función como esta, por ejemplo SHA256, respeta especificaciones estrictas en tres puntos:
-
Dos archivos diferentes no pueden tener la misma suma de control.
-
Un archivo solo puede tener una suma de control.
-
A partir de la suma de control, no es posible encontrar el contenido del archivo de origen.
Esto es empíricamente comprobable con la siguiente prueba:
$ cat archivo1
El contenido del archivo 1.
# sin mayúscula al inicio
$ cat archivo1.bis
el contenido del archivo 1.
#también con una mayúscula en Archivo; después de todo, por qué no
$cat archivo1.ter
El contenido del Archivo 1.
# otra cosa que no tiene nada que ver
$ cat archivo2
El contenido del archivo 2, es más o menos lo mismo.
Cerca de 2kPi, diríamos.
$ sha256sum archivo*
a464400a766b072fb122c6d950b605442b375a18458b6be23c9b1c89c80f4a27 archivo1
27d978894819ae58cd33d556157766773ab53933c84b161aec5d4486fbb09895 archivo1.bis
6afbbdaacb44d8f6d4eb7cee343d00791498d820e9b6273cb370921046becdaa archivo1.ter ...Correspondencias parciales
La principal debilidad de usar las funciones hash en una base de conocimiento radica en el hecho de que modificar un archivo provoca la modificación de todo el hash. Esto es perfecto para garantizar su integridad, pero no es práctico para lo que nos gustaría hacer: saber si dos archivos son parcial o totalmente similares.
Dichos algoritmos existen y se utilizan en particular en correctores ortográficos para aplicaciones de mensajería u otros procesadores de texto, siendo el más conocido la distancia de Levenshtein: https://es.wikipedia.org/wiki/Distancia_de_Levenshtein
Las regex (Regular Expressions) también pueden identificar una coincidencia parcial.
Dichos algoritmos se pueden aplicar al cálculo de hashes, entonces hablamos de fuzzy-hashing.
El algoritmo más extendido consiste en calcular los context-triggered piecewise hashes. Su implementación más conocida es SSDeep: https://ssdeep-project.github.io/ssdeep/index.html
La explicación completa, presentación y el "Paper" en inglés, están disponibles aquí: https://dfrws.org/presentation/identifying-almost-identical-files-using-context-triggered-piecewise-hashing/
Si no ha leído el "Paper", SSDeep calcula hashes en "fracciones" del archivo; como podrá comprobar, es muy revelador.
La visualización del resultado tiene el formato blocksize:hash:hash,filename....
Estructura de un PE e imphash
Para introducir el siguiente concepto llamado imphash, es necesario estudiar el formato de los binarios ejecutables de Windows.
No es necesario entrar en detalles, la versión simplificada del siguiente diagrama debería ser suficiente:
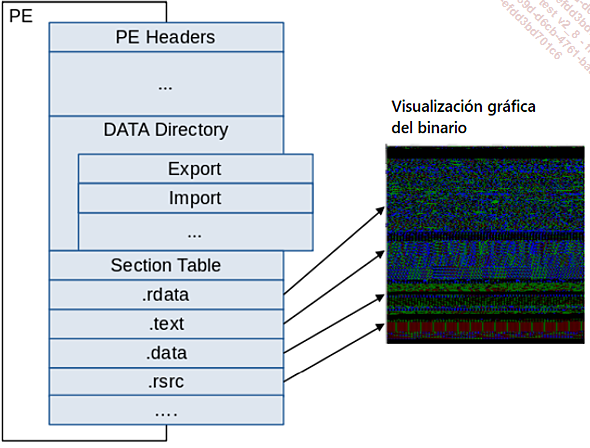
La documentación completa se puede encontrar aquí: https://docs.microsoft.com/es-es/windows/win32/debug/pe-format?redirectedfrom=MSDN
Un binario PE comienza con el encabezado PE, es decir, las letras "MZ". PE (Portable Executable) es el formato propietario de Windows para archivos ejecutables, librerías de desarrollo y otros objetos ejecutables relacionados. Se reconoce fácilmente por la extensión de archivo .exe o .dll o por los dos primeros bytes del archivo en bruto "MZ".
El binario se divide en secciones donde se almacenan los diferentes contenidos. La sección .text es la sección principal, la sección .data contiene las variables, .rdata contiene el contenido auxiliar (en modo readonly) y la sección .rsrc los recursos adicionales (por ejemplo, imágenes).
Si ya ha programado en C, PHP, Java o Python, seguro que sabe que lo primero que debe hacer en su código es importar las librerías necesarias para el programa, para que el compilador prepare las dependencias entre nuestro código y las librerías de nuestro ordenador.
Un binario debe declarar las funciones que pretende utilizar....
Entropía y packing
Dado que es difícil eludir los métodos combinados de impfuzzy + fuzzy hash, un atacante que desee pasar desapercibido deberá modificar todo el binario para lograr su objetivo.
Un enfoque es hacer un segundo binario llamado wrapper. Este último tiene una única misión: servir de caja de transporte opaca para nuestro binario. ¿Un binario dentro de un binario? Se llama concepción binaria. Podemos traducir los verbos "to pack" y "to wrap" por "empaquetar", recubrimos el binario con nuestro "envoltorio especial para regalo": otro binario.
Llegados a este punto, tenemos que hablar de la entropía, un concepto matemático y físico.
Para la fórmula que nos interesa en informática, la entropía de Shannon, es una puntuación entre 0 y 8.
Simplificando, la puntuación representa la cantidad de bits que se necesitan para poder escribir todos los valores contenidos en un archivo.
Por ejemplo, la frase "Le gusta cenar un exquisito sándwich de jamón y bebe zumo de piña con vodka frío " usa todas las letras del alfabeto más el carácter espacio.
Por lo tanto, se necesitan 27 caracteres para escribir este mensaje. Si le damos a cada uno un número entre 0 y 26, podemos escribir el mensaje en formato binario.
No necesitamos 8 bits para codificar los valores del 0 al 27, solo son necesarios 5:
0000 0000 = 0
0001 1011 = 27
Si se utilizan 4 bits, solo se pueden escribir 16 valores (1111 = 15), 5 bits permiten escribir 32 valores (11111 = 31).
El cálculo matemático de la entropía es log2(27) = 4,754887502163469.
La entropía aquí...
Análisis y herramientas
Cada tipo de archivo requiere herramientas específicas, a excepción de unos pocos ejemplares que hacen todo con hexdump y sus scripts C o Python.
Hay distribuciones dedicadas de Linux como REMNux (la distribución orientada a la ingeniería inversa, disponible en https://remnux.org/) o Tsurugi (la distribución orientada a DFIR - Digital Forensic and Incident Response, https://tsurugi-linux.org/).
Si se dedica el tiempo necesario para configurarlo y agregarle algunos paquetes, un buen Debian antiguo funciona igual de bien.
La mayoría están disponibles en los repositorios de Debian (apt) o en los repositorios de pip, aquí hay un extracto de nuestra selección personal:
|
bless |
Editor hexadecimal cona interfaz gráfica |
|
|
ssdeep |
Fuzzy-hashing de archivos |
|
|
EVi |
Visualización gráfica de entropía |
|
|
impfuzzy |
Fuzzy-hashing de las tablas de importación PE |
|
|
Gdb + peda |
Depurador + extensión útil |
|
|
pdfid |
Estudio de los PDF |
|
|
radare2 |
Estudio de los shellcodes |
|
|
oletools |
Estudio de los documentos Office |
|
|
peframe |
Estudio de los PE |
|
|
pefile |
Estudio de los PE |
|
|
yara |
Como un grep en hexa |
|
|
vt-cli |
El cliente para VirusTotal |
|
|
CAPE |
Extracción de los archivos de config y de los payloads... |
Simulaciones y perfilado
Una vez finalizado el análisis de nuestro malware, comienza la fase de clasificación. Para determinar la "malicia" de un código, es posible correlacionar su actividad con las etapas de un ataque.
La realización de un ataque, ya sea como parte de una auditoría de seguridad o como un ataque real, se realiza por etapas. Por ejemplo:
-
Reconocimiento
-
Enumeración
-
Operación
-
Post operación
-
Elevación de privilegio
-
Persistencia
-
C2: Control and Command (Canal de comunicación para controlar máquinas infectadas)
-
Acción sobre el objetivo
Estos pasos pueden variar ligeramente entre modelos, pero la idea generalmente sigue siendo la misma. Por lo tanto, existen puntos comunes entre PTES, OSSTMM, CKC y MITRE Att&ck.
CKC es bastante genérico y se aplica muy bien de forma agnóstica y sobre cualquier tipo de amenaza: Mac, Linux, Windows, red, OT, IoT, móvil...
https://www.lockheedmartin.com/en-us/capabilities/cyber/cyber-kill-chain.html
Sin embargo, el nivel de detalle puede variar. De esta manera, para la matriz MITRE Att&ck, el número de pasos aumenta y se detallan todos ellos.
Sin embargo, esta especialización tiene un precio, ya que para ser exhaustivos en las técnicas de ataque es necesario elegir una tecnología sobre la que se aplican. Por lo tanto, MITRE Att&ck, como era de esperar, elige Windows, perdiendo la capacidad...
Sitios de clasificaciones y sandboxes
Para ayudar a establecer una clasificación, hay muchas herramientas disponibles.
-
Bases MISP
-
Sandboxes públicas
-
Soluciones de clasificación/comparativas
-
Ajustes YARA
Todos los enlaces de este capítulo están disponibles en formato de texto para copiarlos y pegarlos fácilmente: https://gist.github.com/twpZero o https://bit.ly/3vr467c
Ediciones ENI ha publicado un libro perfectamente adaptado para dar seguimiento a este capítulo: "Seguridad informática y malware" escrito por Paul Rascagnères. Este libro está en castellano, e inicialmente tenía el título "Malwares". Me sirvió como guía efectiva en mis inicios y la edición de 2013 todavía está en mi escritorio.
Hay muchos libros disponibles para obtener más información sobre ingeniería inversa y análisis de malware. Una simple búsqueda en Google debería dar buenos resultados: "malware analysis books" o "libro de análisis de malware".
Buen viaje.
